
Der Kontext-Layer im KI-Betriebssystem
Wie KI alles lernt, was Dein Unternehmen weiß.
Herzlich Willkommen zu den AI FIRST Insights! Unser Ziel mit dem KI-Betriebssystem war von Anfang an, dass KI Arbeit so erledigt wie wir selbst und mit jeder Weiterentwicklung der KI-Fähigkeiten mit skaliert. Nicht „so ungefähr" – sondern so, dass das Ergebnis sofort passt. Damit das funktioniert, muss die KI denselben Wissensstand haben wie wir. Sie muss unsere Kunden kennen, unsere Produkte, unseren Ton, unsere Entscheidungslogik. Kurz: Wir müssen alles Implizite explizit machen.
Dafür haben wir einen Kontext-Layer aufgebaut.
Heute zeige ich, wie wir den Kontext-Layer strukturiert haben, wie wir über Kontext nachdenken und was dabei die wichtigsten Erkenntnisse waren.
Los geht's!
Was ist der Kontext-Layer?
Ich habe in den letzten Wochen viel über Skills geschrieben – wie man sie baut, wie man sie dokumentiert, wie man sie ausführen lässt. Aber als wir die ersten Skills produktiv eingesetzt haben, wurde schnell klar: Ein Skill ohne Kontext ist wie eine Arbeitsanweisung für jemanden, der am ersten Tag neu ins Unternehmen kommt und noch keinen Zugang zu irgendeinem System hat. Die Anweisung kann noch so gut sein – ohne das Wissen drumherum wird das Ergebnis nicht gut genug.
Unser größtes Problem war also nicht die KI selbst – es war, was die KI nicht wusste. Ich konnte ihr einen perfekt dokumentierten Skill geben, aber wenn sie nicht wusste, an wen sich unser Angebot richtet, wie wir intern kommunizieren oder welche Projekte gerade laufen, war das Ergebnis bestenfalls ein brauchbarer Entwurf.
Kontext ist das, was den Unterschied macht zwischen brauchbarer Entwurf und erledigter Aufgabe. Wenn ich ein Angebot erstelle, kennt die KI unsere Produkte, unsere Preisstruktur, den bisherigen Gesprächsverlauf mit dem Kunden und meinen Schreibstil. Wenn ein Kollege dasselbe tut, kennt sie seinen. Wir nutzen beide denselben Skill – aber der Kontext individualisiert das Ergebnis. Mit Kontext ist der erste Entwurf in 90% der Fälle direkt nutzbar.
Der Kontext-Layer ist unsere Antwort darauf. Er ist die strukturierte Sammlung von allem, was die KI über uns und unsere Organisation wissen muss. Dabei war uns früh klar, dass „alle Dokumente in ein KI-Tool kippen" nicht die Lösung ist. Wir haben das am Anfang selbst versucht – und gemerkt, dass zu viel unstrukturierter Kontext die Ergebnisse nicht verbessert, sondern verschlechtert. Die KI ertrinkt im Rauschen.
Was stattdessen funktioniert, ist ein bewusst kuratiertes Wissensregister – mit klaren Referenzen auf die richtigen Quellen, einer Logik dafür, wann welche Information geladen wird, und einer Verknüpfung zu den Skills, die diese Information brauchen. Jeder Eintrag beantwortet drei Fragen: Was ist die Quelle, wann wird sie gebraucht, und welcher Skill braucht sie?
Ein Prinzip, das sich dabei als zentral herausgestellt hat: Referenzieren statt Kopieren. Unsere Kontext-Einträge verweisen auf lebende Dokumente – Seiten und Datenbanken in unserem System, aber das funktioniert genauso mit einem Wiki, einer Cloud-Ablage oder einem internen Wissenssystem. Wenn sich die Quelle ändert, ist der Kontext automatisch aktuell – kein manuelles Nachziehen an drei Stellen.
Wie wir den Kontext-Layer aufgebaut haben
Unser Kontext-Layer besteht aus zwei Schichten. Der persönliche Kontext beschreibt, wer du bist. Der aufgabenspezifische Kontext beschreibt, was für eine konkrete Aufgabe gebraucht wird.
Der persönliche Kontext
Jeder bei uns im Team hat ein persönliches Kontextprofil – fünf eigenständige Dokumente, die bei jeder KI-Interaktion automatisch mitgeladen werden:
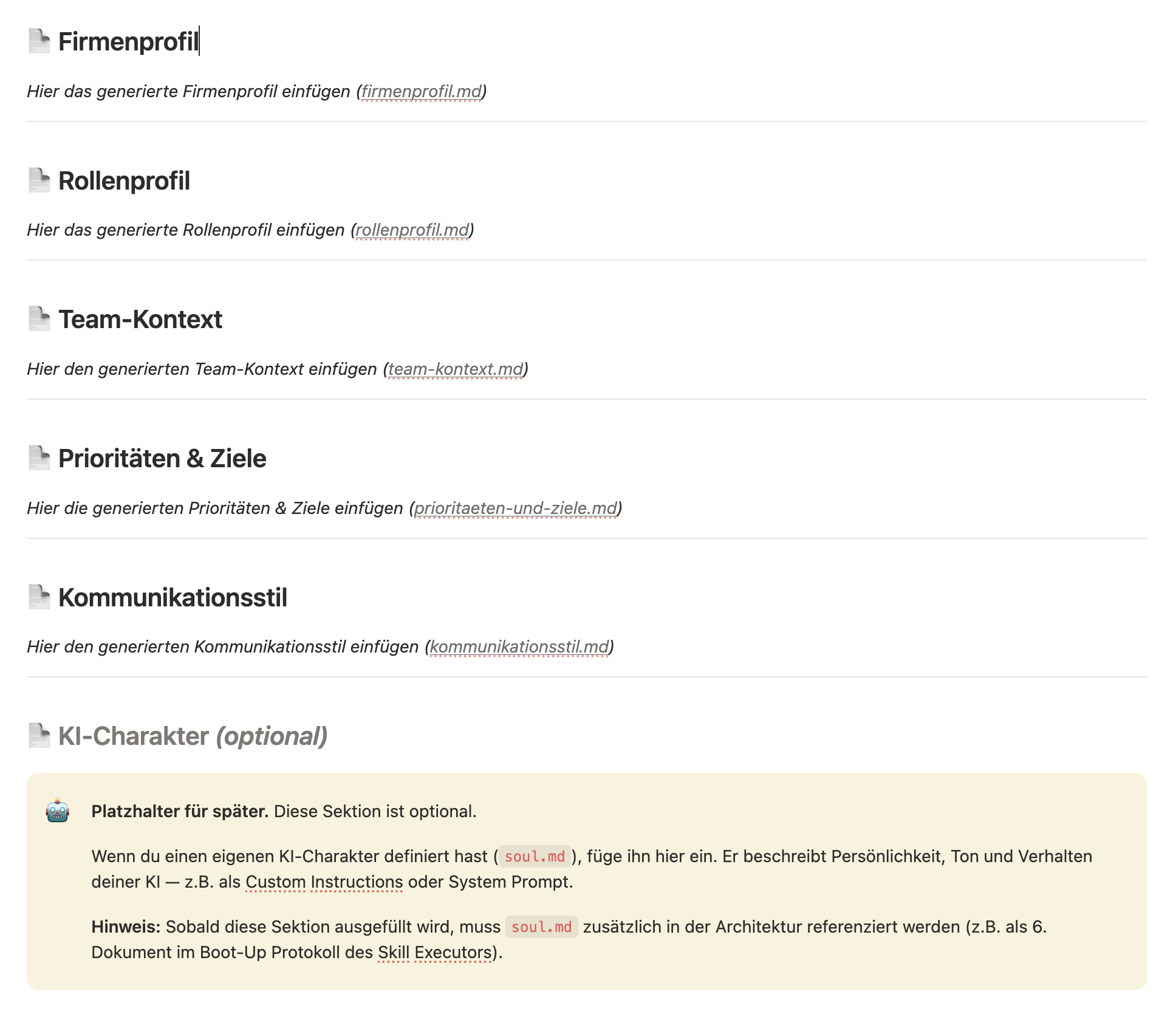
- Firmenprofil – Was macht AI FIRST, für wen, wie positionieren wir uns?
- Rollenprofil – Was ist meine Position, was sind meine Verantwortlichkeiten, mit welchen Tools arbeite ich?
- Team-Kontext – Wer arbeitet zusammen, wann muss wer einbezogen werden?
- Prioritäten & Ziele – Was ist gerade wirklich wichtig, welche Projekte laufen?
- Kommunikationsstil – Wie klingt mein Ton intern und extern, was sind Do's und Don'ts?
Nicht alle fünf werden immer geladen. Firmenprofil, Rollenprofil und Kommunikationsstil bilden den Kern – die kommen bei jeder Interaktion mit. Team-Kontext und Prioritäten nur dann, wenn die Aufgabe es erfordert. Das ist wichtig, weil jede Information im Kontextfenster Platz und Aufmerksamkeit kostet.
Für die Erstellung dieser Dokumente haben wir ein KI-geführtes Interview entwickelt. Statt selbst zu schreiben, führt die KI einen Block für Block durch alle fünf Bereiche und fragt so lange nach, bis jedes Dokument konkret genug ist. Wir nutzen das mittlerweile auch mit unseren Kunden – 60 Minuten, und das Kontextprofil steht und verbessert anschließend jede einzelne Aufgabe. Es funktioniert plattformübergreifend in Claude, ChatGPT, Copilot oder jedem anderen System, weil die Dokumente einfache Markdown-Dateien sind.
Ein Einwand, der dabei immer wieder kam, auch bei uns intern: „Wenn der Kontext nicht fest eingebettet ist, sondern jedes Mal geladen werden muss, wird das doch langsamer und teurer." Das klingt logisch, stimmt aber nicht. Die Token-Kosten sind identisch – der Kontext landet so oder so im Kontextfenster. Eingebetteter Kontext ist sogar teurer, weil immer alles mitgeladen wird, auch wenn die aktuelle Aufgabe es nicht braucht. Seit wir auf selektives Laden umgestellt haben, sind unsere Ergebnisse besser geworden, nicht schlechter.
Der aufgabenspezifische Kontext
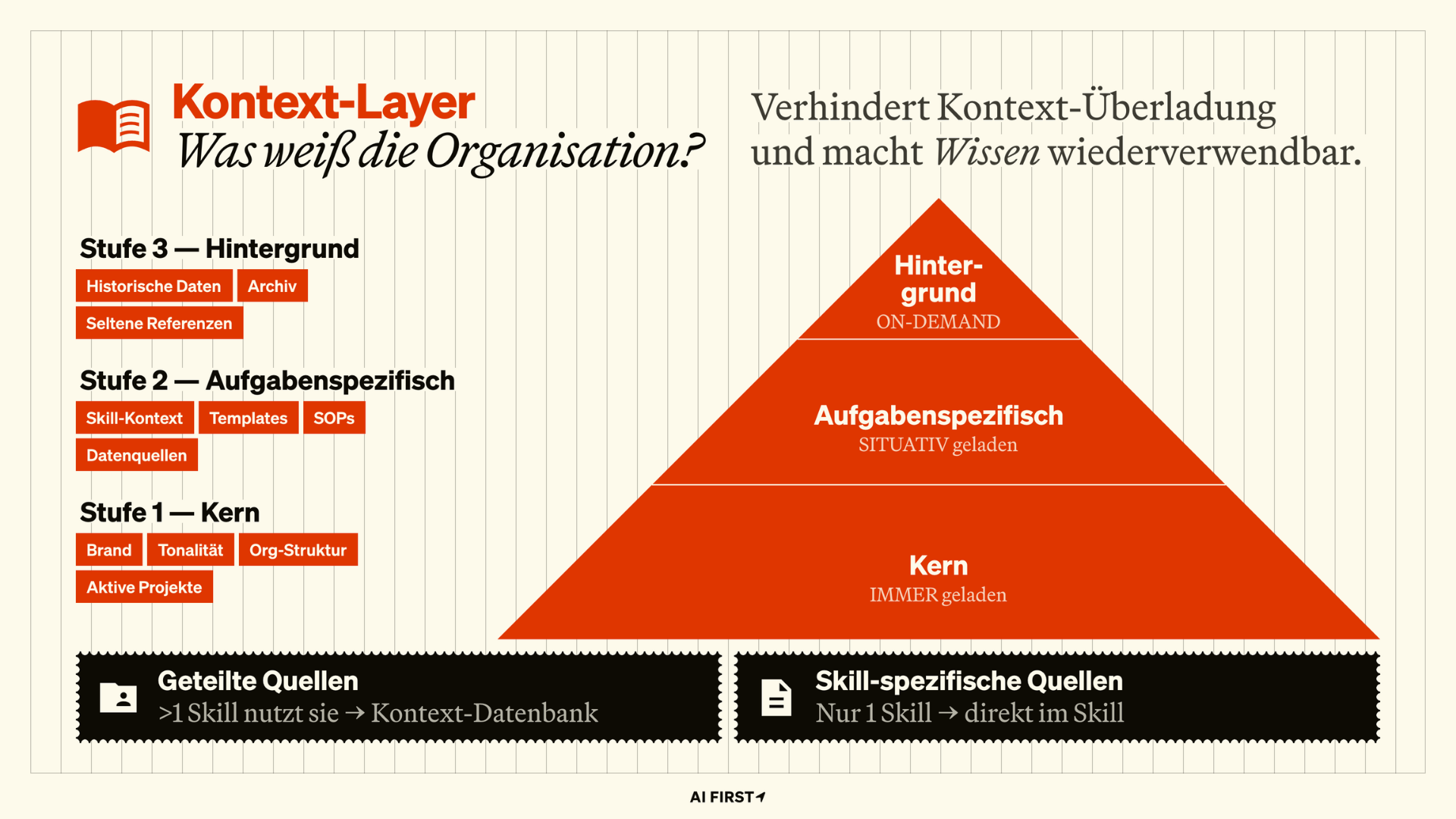
Neben dem persönlichen Kontext brauchen einzelne Skills aufgabenspezifisches Wissen – Vorlagen, Kundendaten, Produktdokumentation, Prozessbeschreibungen. Dieses Wissen organisieren wir in einem zentralen Wissensregister mit einer dreistufigen Hierarchie:
- Stufe 1 (Kern): Wird immer geladen. Die Grundlagen, ohne die kein Skill starten kann.
- Stufe 2 (Aufgabe): Wird nur geladen, wenn ein bestimmter Skill es braucht. Beim Onboarding zum Beispiel: das Master-Template für den Projekt Hub, bestehende Projekte für den Duplikat-Check.
- Stufe 3 (Hintergrund): Kommt nur auf explizite Anfrage dazu – historische Projektdaten, Langzeit-Trends, Archivmaterial.
Diese Aufteilung hat sich für uns als einer der größten Hebel erwiesen. Mehr Kontext bedeutet nicht automatisch bessere Ergebnisse – oft passiert das Gegenteil. Zu viel Information erzeugt Rauschen und die KI verliert den Fokus. Die Stufen-Logik sorgt dafür, dass sie genau das bekommt, was sie für die aktuelle Aufgabe braucht.
Kontext aktuell halten
Der beste Kontext-Layer ist wertlos, wenn er veraltet. Einmal dokumentieren reicht nicht. Unser Design-Prinzip dafür ist simpel: Es darf keine Lücke geben zwischen dem, was im Unternehmen passiert, und dem, was im Kontext der KI zugänglich ist.
Konkret heißt das bei uns: Jedes Meeting wird aufgezeichnet, transkribiert und strukturiert in einer Datenbank gespeichert. E-Mails fließen ins System. Kundenprojekte werden dokumentiert, während sie laufen – nicht irgendwann nachträglich. Content, den wir produzieren, ist sofort Teil des Kontexts für zukünftige Aufgaben. Es gibt keinen Moment, in dem etwas Relevantes passiert und die KI nichts davon mitbekommt.
Weil unsere Kontext-Einträge auf lebende Dokumente verweisen statt auf Kopien, müssen wir auch bei Prozessänderungen nichts manuell nachziehen. Die Quelle wird aktualisiert – und jeder Skill, der darauf zugreift, arbeitet automatisch mit der neuen Version.
Für eine fortlaufende Bereinigung und Aktualisierung haben wir einen ersten Agent gebaut, der monatlich eine umfangreiche Prüfung der Kontext-Datenbank sowie der dahinterliegenden Quellen vornimmt, mit unseren Mails und Meetings abgleicht und Lücken im Kontext oder veraltete Informationen aufzeigt.
Von implizit zu explizit
Wenn ich heute auf den Prozess zurückblicke, war die eigentliche Arbeit am Kontext-Layer nicht technisch. Der schwierigste Teil war die Erkenntnis, wie viel von dem Wissen, das unser Unternehmen ausmacht, nirgendwo aufgeschrieben war. Es steckte in meinem Kopf, im Kopf von Kollegen, in E-Mail-Verläufen, in Meetings, die niemand dokumentiert hatte. In Entscheidungen, deren Begründung ich selbst nicht mehr nachvollziehen konnte.

Das ist in den meisten Unternehmen so – und es war auch nie ein Problem, solange Menschen die einzigen waren, die mit diesem Wissen arbeiten mussten. Aber wenn KI denselben Job machen soll, braucht sie Zugang dazu. Und dafür muss es aufgeschrieben sein.
Der erste Schritt, den wir gemacht haben – und den wir mittlerweile auch jedem Kunden empfehlen – ist eine ehrliche Bestandsaufnahme: Welche Systeme nutzt ihr? Wo liegt welches Wissen? Was davon ist digital und für eine KI zugänglich – und was steckt noch in Köpfen, E-Mails oder Aktenordnern? Diese Inventur klingt banal, aber bei fast jedem Unternehmen, mit dem wir arbeiten, wird erst dabei klar, wie fragmentiert das Wissen tatsächlich verteilt ist.
Man muss nicht alles auf einmal machen. Wir haben mit den fünf wichtigsten Quellen angefangen – die Dokumente und Datenbanken, auf die wir am häufigsten zugegriffen haben. Die bekamen eine Stufe, eine Verknüpfung zu den relevanten Skills, und von da aus haben wir Stück für Stück erweitert. Heute haben wir über 40 Kontext-Quellen in unserem Register.
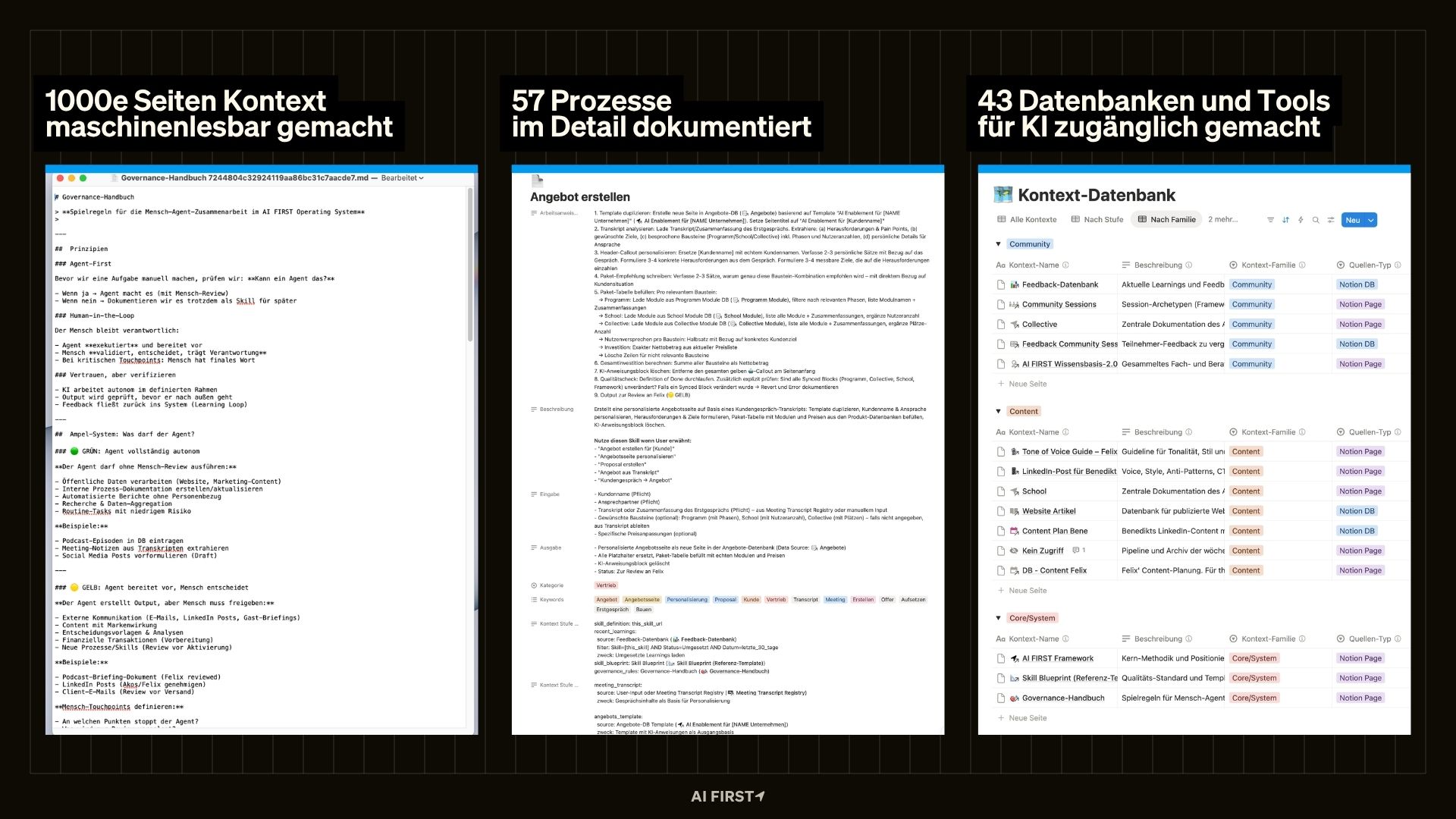
Der Prozess hat nicht nur die KI besser gemacht. Er hat auch unsere Zusammenarbeit als Team verbessert. Plötzlich ist dokumentiert, was vorher nur in einzelnen Köpfen existierte. Neue Teammitglieder werden schneller produktiv. Und Entscheidungen werden nachvollziehbar, weil die Logik dahinter endlich irgendwo steht.
🏁 Fazit
Kontext ist der Baustein, der alle anderen im KI-Betriebssystem erst wirksam macht. Ohne Kontext sind Skills nur generische Vorlagen. Ohne Kontext sind Agenten nur Automationen, die im Blindflug arbeiten. Erst wenn die KI denselben Wissensstand hat wie wir, entsteht das, was wir mit dem KI-Betriebssystem erreichen wollten: eine KI, die Arbeit so erledigt, wie wir es selbst tun würden.
Der Weg dahin war keine technische Herausforderung. Es ging darum, das implizite Wissen unserer Organisation sichtbar zu machen. Das hat sich anfangs ungewohnt angefühlt, aber es ist die Investition mit dem größten Hebel, die wir in den letzten Monaten gemacht haben.
Wer anfangen will: Starte mit deinem persönlichen Kontextprofil. Wenn du unseren Interview-Prompt haben willst, schreib mir gern.
Im nächsten Artikel steige ich tiefer in den nächsten Baustein ein: die Governance. Welche Regeln braucht ein System, in dem KI einen immer größeren Teil der Arbeit übernimmt? Wie definiert man, wo Autonomie endet und ein Mensch übernimmt? Und wie stellt man sicher, dass die Regeln nicht nur auf dem Papier stehen, sondern bei jeder Ausführung tatsächlich greifen?
Bis nächsten Sonntag,
Felix
P.S. Wie stellt ihr eurer KI den Kontext bereit, den sie benötigt? Ich freue mich über Erfahrungen!
Registriere dich kostenlos,
um den vollständigen Artikel zu lesen.
vollständige Insights
Hub-Werkzeugen
und diskutiere mit
an einem Ort






